
Context
Some early years qualifications have additional requirements. If these are not met, the qualification may not be considered full and relevant.
When that happens, the qualification holder can only work as an unqualified member of staff — unless there are alternative routes that let them work at specific staff:child ratios.
There is an exception to this rule, if users are checking a qualification that:
- is a level 3 or above
- was started between 1 September 2014 and 31 August 2019
In this scenario, we could not give users a definite answer. This is because the qualification could potentially allow the qualification holder to work at level 2, but only if both of these additional criteria apply as well:
- the qualification is early years (0 to 5 years) related
- the qualification is appropriate to early years practice
Initial design
If the qualification is on the early years qualifications list (EYQL)
If users can find the qualification in the service, they will navigate to the qualification result page. Because we could not tell users that the qualification was not approved, we introduced a new tag status against level 2 on this page: ‘Further action required’.
This status made it clear that we could not give them a result and that they needed to do further checks. We also gave them the option to contact the Department for Education (DfE) for help.
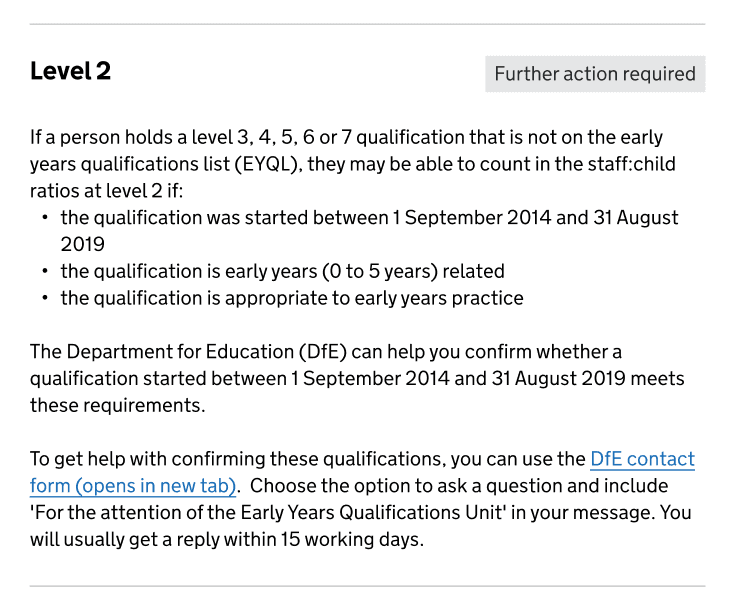
For a qualification holder to work in the staff:child ratios at level 2, the qualification must meet all of the following:
- is not full and relevant
- is a level 3 or above qualification
- was started between 1 September 2014 and 31 August 2019
- the qualification is early years (0 to 5 years) related
- the qualification is appropriate to early years practice
If the qualification is not on the list
If the qualification is not on the EYQL spreadsheet, it does not appear in the service. This means it will not show as an option to select on the 'Select a qualification to check' page, and the user will not be able to get to a result page for that qualification.
Instead, we tell users to visit the 'I cannot find the qualification' page.
There are 21 versions of this page, all tailored to the date and level the user entered. For example, there is a version of this page which is only shown when the user checked a level 3 qualification started between 1 September 2014 and 31 August 2019.
On versions of this page where working at level 2 is possible, we explain how a qualification holder may be able to count in the staff:child ratios at level 2.
In this section we also tell users that the qualification holder can work as an unqualified member of staff. If the qualification is level 3 or above, we also explain that the holder may be eligible for the experience-based route.
Example of a version of the ‘I cannot find the qualification’ page for a level 3 or above qualification started between 1 September 2014 and 31 August 2019:

The same information also appears on the guidance pages for level 2 and level 7 qualifications started between 1 September 2014 and 31 August 2019. On the level 7 page we explain that the holder may be eligible for the experience-based route. This information does not appear on the level 2 page, as the qualification must be level 3 or above to be eligible.
Guidance page for Level 2 qualifications started between 1 September 2014 and 31 August 2019:

Research findings
During research, participants struggled to understand the content under level 2. Many thought they needed to check another qualification that candidates might have achieved before the one they were checking for. The ‘Further action required’ status also caused confusion.
All participants felt that the 15 working-day response time to get help from DfE was too long. Waiting for a reply risked slowing recruitment and losing candidates to another job.
Working with policy
We collaborated with policy colleagues to explore how we could make the process easier in these scenarios.
We mocked up different variations of the content under level 2, considering 3 approaches:
- give users an answer
- ask manager to decide
- still require confirmation from DfE
It was agreed that where we know that, were it not for their answers to the additional requirement questions, the qualification would be full and relevant, we would give users an answer and tell them that the qualification is approved at level 2. This does not mean it is considered full and relevant because this depends on their answers to the additional requirement questions for that qualification.
Design iteration
Based on the research findings and our policy discussions, we made 2 key updates to the qualification result page:
- revised the content under level 2 for cases where users are checking a level 3 or above qualification that is not full and relevant, but was started between September 2014 and August 2019
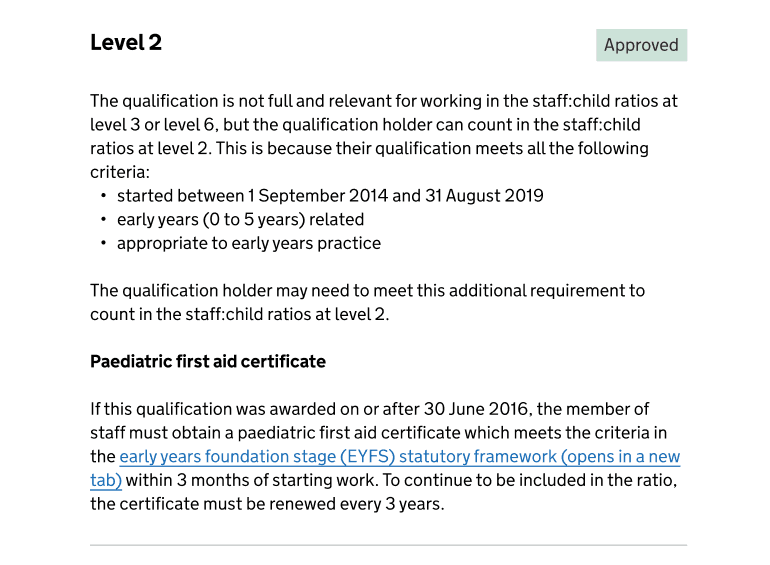
- changed the status at level 2 from ‘Further action required’ to ‘Approved’
We made these changes because these qualifications are on the EYQL spreadsheet and are potentially full and relevant. However, the user’s answers to the additional requirement questions mean they are not considered full and relevant at the higher level.
By updating the content and status, we now clearly explain that the qualification holder can work in staff:child ratios at level 2 and why this is the case.
Now that we tell users the qualification is approved at level 2, we also explain the Paediatric First Aid (PFA) certificate requirement:
- If the qualification was awarded in June 2016: the content states that the qualification holder may need to hold a PFA certificate. This depends on whether the award date was before 30 June or on 30 June.
- If the qualification was awarded after June 2016: the content states that the qualification holder must hold a PFA certificate.
Example of the content displayed under level 2 and its new status for a level 3 or above qualification that is not full and relevant but was awarded between 1 September 2014 and 31 August 2019:
The content on the ‘I cannot find the qualification’ page and the Level 2 and Level 7 qualifications started between 1 September 2014 and 31 August 2019 guidance pages remained the same, since we cannot identify the qualification being checked when users visit the ‘I cannot find the qualification’ page, we left that content as it is. These users can still contact DfE for advice if they feel they need it.
Next steps
We will monitor queries and feedback about Level 3 or above qualifications that are not full and relevant but were started between 1 September 2014 and 31 August 2019. This will help us understand whether the changes have reduced confusion about the Level 2 content and status.
If we conduct further user research, we may include this journey to test how the changes perform in practice.