
An introduction to Pathways
This Pathways programme for children’s social work managers and supervisors ended in 2024. It was a government-funded, face-to-face training course delivered by Frontline.
We wanted to keep the valuable resources from this training programme so we can continue to support leaders and managers in social work.
We created the Pathways leadership modules, based on the skills taught on the Pathways programme, in partnership with Frontline.
The problem
When the Pathways leadership modules content was first published on the Support for social workers (SfSW) website, it did not include breadcrumbs or back links, which made it difficult for our users to navigate this content smoothly.
While the content encourages users to progress though the Pathway modules in a linear journey from start to finish, we also need to give them a way to navigate away from the content and go to other sections of that Pathway or one of the other Pathways if they wish.
This work was prompted by:
- feedback from a design crit in February 2025
- accessibility concerns raised from light-touch testing
- inconsistent use of breadcrumbs and back link components across the service
Our aim was to:
- improve navigation and accessibility
- create consistent rules for using breadcrumbs and back link components across the service
Researching and exploring our options
We took a team approach to researching and exploring our options. This included developers, content and interaction designers, the business analyst, and product manager.
We mapped the Pathways journey from the home page all the way to the start of the pathway course in Figma and Lucid, reviewing previous designs, and identifying areas for improvement.
We also researched the Government Design System, NHS Design System, and Nielsen Norman Group best practices for using breadcrumbs and back link components.
Key issues we found during our investigation included:
- missing breadcrumbs and back links
- inconsistent use and naming
- accessibility concerns
- difficulty navigating between the 4 different Pathway modules
To support navigation through the Pathways modules we considered and explored 3 main options. These were to use:
- both breadcrumbs and back links
- only back links
- only breadcrumbs
We sketched ideas, listed risks and assumptions, and gathered feedback from other designers and services, including the DfE Patterns and Components working group.
Key design decisions and rationale
We decided to use a combination of breadcrumbs and back links based on our research.
Back link challenges in Pathways modules
We wanted the back links to appear when users reach the module content, as this is the start of their linear journey. The back links were enabled for users to return to the contents page for a module or back to the Pathways modules landing page.
Updating the breadcrumbs was straightforward but the back links presented us with some challenges to consider. We knew that:
- there was no time for user research or testing, due to the time constraints
- developers would need to make the changes because the back links were built into the programme (hard coded), both now and in the future
- we needed a solution that could be easily implemented by the content designers in Contentful
Back links in the Pathways content had been hard coded to start on the course contents page, rather than the start of the training module itself.
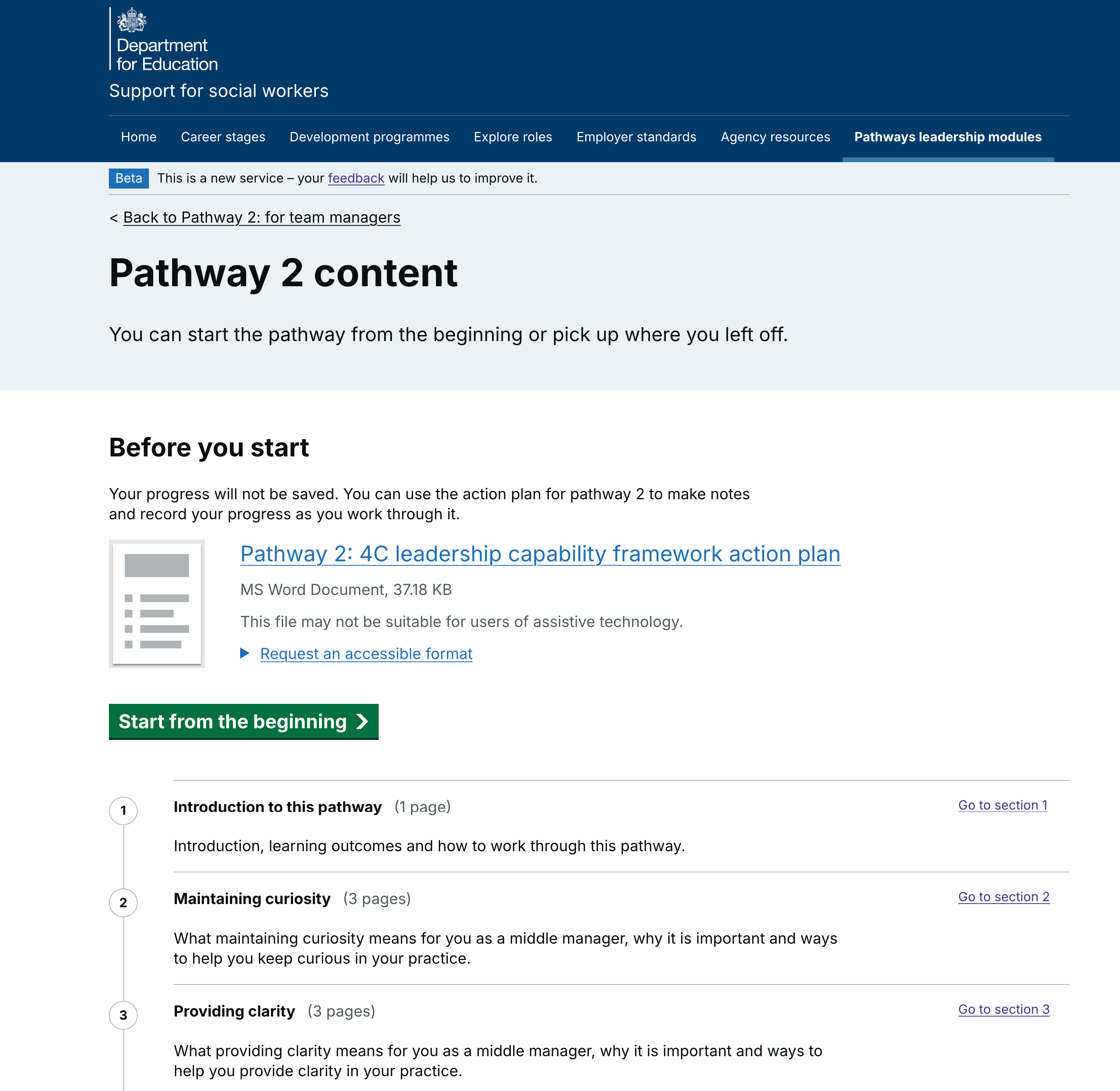
We considered:
- keeping back links as they are (starting before course content)
- moving the back links to start at module content
- making the back links that can be updated and edited without changing the code
We ran a ‘three amigos’ session with a mixed group of disciplines from within our digital team. As a group, we chose to keep the back links as they are because:
- this requires less development work
- Pathways is legacy content and not a priority
- usage data (from GA4) shows low engagement
- changing the code could introduce errors
- they automatically update
- inputting manual back links has an impact on team workload (content and quality assurance)
- there is less room for human error
Refining the use of breadcrumbs across the service
We refined our designs based on:
- feedback from design crits
- accessibility testing
- developer constraints
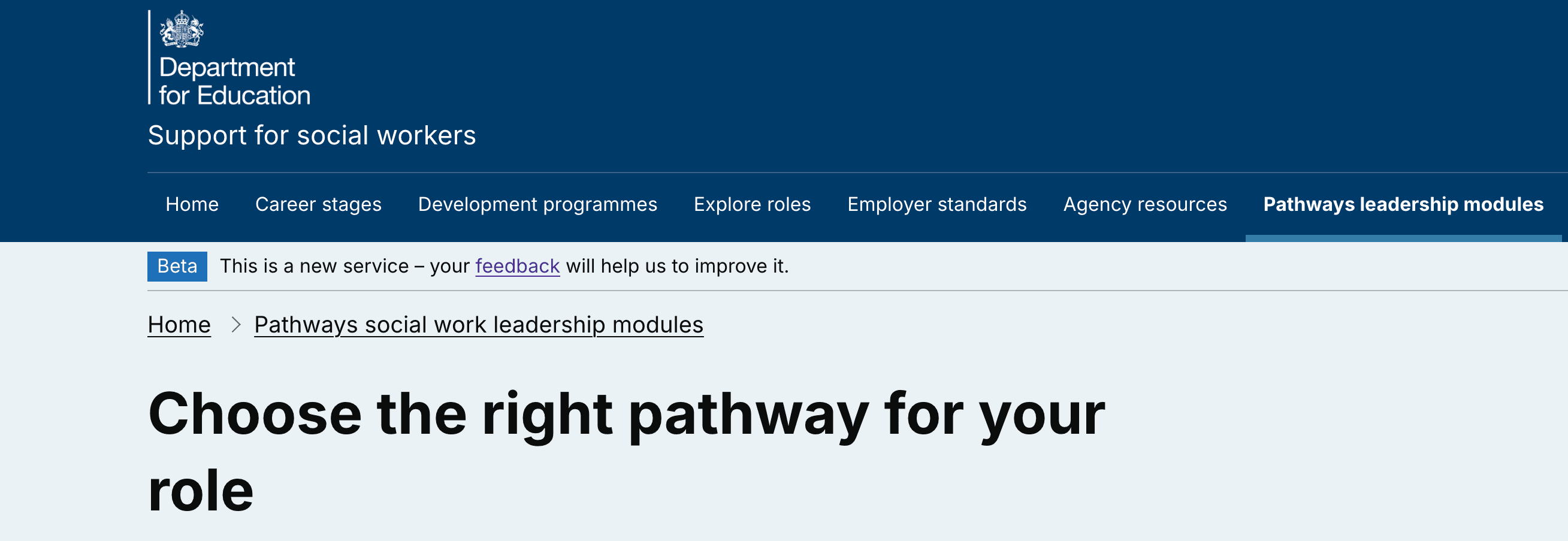
Key changes included:
- updating breadcrumb structure to match the Government Design System
- making the last breadcrumb non-clickable to avoid redundant links
- ensuring breadcrumbs and back links match page heading level ones
- ensuring breadcrumbs and back links update automatically if heading text changes
Implementing our design and its impact
We kept the existing breadcrumb and back link structure and improved naming for clarity and accessibility.
The final designs:
- help users understand where they are in the service
- improve consistency across the site
- reduce the need for further development work
- reduce the risk of error
- reduce the volume of content to be quality assured
- improve accessibility and navigation
- are consistent with other government services
We learnt a lot about the use of breadcrumbs and back links doing this work. Working in the open and early collaboration with developers and business analysts was crucial to the development of the designs and the decisions we made.
Creating clear guidance
We turned our learnings into clear guidelines on when to use breadcrumbs and back links, and how to apply them.
Our guidelines are a work in progress and are a starting point for future evidence-based changes to our service.
| Guideline | Description |
|---|---|
| Do not have the current page as an active link within the breadcrumb structure. | On the breadcrumb structure the last interactive link should always be the parent section to the current page you are on. |
| Breadcrumbs should always start with home and end with the breadcrumb of the parent section of the page you are on. | The last breadcrumb on the page should be the parent section of the current page. This should be an active clickable breadcrumb. |
| Back links should be in the format ‘Back to [page]'. | For consistency across the site, all back links should say ‘Back to …[page name]’. |
| Breadcrumbs and back links should always match the H1 of the page it leads to. | The breadcrumbs should always match up to the page it leads to. Back links should also contain the name of the page in the format ‘back to…[page name]’. |
| Breadcrumbs should be used as a default unless there is a transactional/linear activity. | Breadcrumbs for our service are a standard as it is a deep hierarchy structure due to many layers of navigation. Back links can be used for transactional or linear actions (such as a linear course - pathways) however research may be necessary to see what is best for your users. For similar content which is separated on our service the breadcrumb/ back link structure should be consistent. |
| Having back links for the start of the course/transactional section. | As stated previously, back links can be used for transactional or linear actions (such as a linear course - pathways) however research may be necessary to see what is best for your users. Research may be required to know how and when to use back links on our service. |
| Do not continuously switch between breadcrumbs and back links | When using both breadcrumbs and back links do not switch between them interchangeably. It will get confusing for users. |
| Do not use breadcrumbs and back links on the same page | Do not use breadcrumbs and back links on the same as one another as this is confusing for users as well as duplicating links that do the same thing but appear different. |